1. 분석컨설팅
1-1. 분석시나리오 정의
현 상황을 해결하기 위한 방법론 정의 - 서술형 전개 방식 !!!!!!!!!!!!!!!!
예시)
1) y 분포 가정
2) link 함수 설명
3) 잔차 plot/AIC 모델 확인
LM(선형회귀모델): 종속변수가 정규분포 only
- 정규분포된 오차를 갖는 데이터에 피팅
GLM: 종속변수 평균 정해진 함수로 변환한 값 - 독립변수 선형결합 형태
ㄴ 정규분포 제약 없어져 실제 데이터 다룰 수 있게 됨
(확장)
1) 연결 함수 추가를 통해 모수의 선형성에 대한 가정이 완화
2) 정규분포와 다른 오차 분포를 모델링
| 종속변수 확률분포 | 최적 Link function | |
| 정규(LM) | 항등, 가우시안 | = LM |
| 이항(y 이진) | logit, binomial | = 로지스틱 회귀모형 |
| 감마(y > 0) | negative inverse | (skew) 감마 ※ > 0 은 전처리 단계에서 충분히 큰 상수 더해서 해결 - y가 금액일 때 가정 |
| 포아송(독립시행O) | log, poisson | (이산형) (시간/공간) 단위 시간당 도착하는 이벤트의 수 |
| 음이항(독립시행X) | log | (이산형) <성공관련> 연별 교차로 차사고 수, 공정 실패 횟수 |
※ link function: 종속변수 기댓값을 설명변수 선형 결합으로 표현할 수 있게 변환
※ 종속변수가 순위나 선호도 같이 '순서'만 있는 데이터: ordinal regression
- ML 방법론
- CRISP-DM: Business understanding > Data understanding(EDA/CDA) > Data Preparation > Modeling > Evaluation > Development
- CDA(Confirmatory Data Anlaysis): 탐색으로 파악하기 애매한 정보는 통계적 분석 도구(가설 검정) 사용
- CRISP-DM: Business understanding > Data understanding(EDA/CDA) > Data Preparation > Modeling > Evaluation > Development
- 이상탐지
- 유형(3): Point(정상 범위) / Contextual(정해진 패턴) / Collective(데이터 간 관계가 기존과 다름)
- 통계: IQR, 3시그마(=ESD)(양쪽 평균 3표준편차, 68-95-99.7)
- 시계열: ARIMA(AO, LS, TC)
- 군집화, One-class SVM, AutoEncoder(재현시 오차가 클수록)
- Isolation Forest(랜덤 분류 > 고립되기까지 노드 수 >> 빨리 고립되는(노드 수 적은) 경우)
- (-): 설명력, 파생변수 생성 필요, 장기적 패턴 반영 어려움
- S-H-ESD = MAD(중위수 절대 편차) + S-ESD(Seasonal) : 이상치 영향 적고 시계열성/트랜드 반영
- 다변량 통계 분석 이상탐지 기법: 데이터 차원 축소, 잔차 벡터 계산하여 이상치 탐지(크면 이상치 가능성 높음)
1) T2 (Hotelling's T2 statistic): 차원 축소된 표현에서의 관측치의 잔차 벡터와 데이터의 중심(평균) 사이의 거리
2) SPE (Squared Prediction Error): 차원 축소된 데이터 원래 차원으로 복원한 후, 복원된 데이터와 원본 데이터 사이의 잔차 벡터의 크기 제곱 측정
- 모델 개발/방안 정의
- 모델 운영방안 정의
- 파생변수의 형태 정의
- Encoder의 형태 정의
- 데이터마트의 형태 정의
- 원천 데이터(raw data)를 목적에 맞게 가공*요약한 분석용 데이터
- row = 관측치(observation) | column = 변수(variable)
- 동일 개체 시점 반복 측정 시, row = 측정 시점
- 원천 데이터(raw data)를 목적에 맞게 가공*요약한 분석용 데이터
1-2. 분석 방법론 구체화(위치 이동)
2. 데이터탐색 및 기초통계분석
2-1. 기초통계분석
- 요약 통계량의 이해
- 용어
| 백분위수 | (percentile) 전체 데이터의 P% 아래 두는 값(중간값median = 50번째 백분위수) |
| 사분위범위 | (IQR: Inter Quartile Range) = Q3 - Q1, outlier = Q1 - 1.5 * IQR & Q3 + 1.5 * IQR |
| 절사평균 | (trimmed mean) 정해진 개수의 극단값 제외한 나머지 값들의 평균(=절단평균) |
| 강건성 | (robust) 극단값에 민감하지 않다 |
| 편차 | (deviation) 위치 추정값 - 관측값 |
| 분산 | (variance) 평균 - 관측값(평균과의 편차)를 제곱한 값들의 합을 n-1 로 나눈 값 ※ 분산의 제약조건: 평균의 평균에 따른다(1개) 자유도 n-1 ※ n으로 나누면 편향 추정(모집단 분산과 표준편차 참값 과소/대 평가), n-1로 나누면 비편향 추정 |
| 표준 편차 | (standard deviation) 분산의 제곱근 |
| 중간값의 중위절대편차 |
(MAD: median absolute diviation from the median) 중간값과의 편차의 절대값의 중간값(강건) ※ 분산, 표준편차, 평균절대편차 강건 X ※ (정규분포 가정) 분산, 표준편차 > 평균절대편차 > 중위절대편차 |
| 기댓값 | (expected value) 범주의 출현 확률에 따른 평균 |
-
- 가설검정
- 귀무가설: 현재까지 받아들여지는 주장(연구자 기각 목표!)
- 대립가설: 연구자 주장 가설
- p-value(유의확률α): < 0.05 귀무가설 기각 = 대립가설 채택 = 유의수준 α하에서 통계적 유의미
- : 귀무가설이 맞다고 가정할 때 얻은 결과보다 극단적인 결과(대립가설)가 실제로 관측될 확률
- 신뢰구간: 모평균이 포함되어 있을 구간의 확률(구간이 클 수록 구간에 모수가 포함될 가능성 大)
- 표본 사이즈 ↑ > 신뢰구간 좁아짐 & margin of error(오차한계) 작아짐 == 더 정확하게 모집단 평균 추정 가능
- 확률적인 해석 불가능
- 가설검정
-
- 신뢰수준: 같은 모집단으로부터 같은 방식으로 얻은, 관심 통계량을 포함할 것으로 예상되는, 신뢰구간의 백분율
- 표본이 작을수록 구간이 넓어짐(불확실성이 더 커짐)
- 신뢰수준: 같은 모집단으로부터 같은 방식으로 얻은, 관심 통계량을 포함할 것으로 예상되는, 신뢰구간의 백분율
-
- 불편추정량: 표본평균을 다시 평균(표본평균의 기댓값)하여 모평균 추정
- 표준정규분포: x축 단위가 평균의 표준편차로 표현되는 정규분포
- 정규화/표준화: 데이터 - 평균 / 표준편차 => z점수 (z score)
- 중심극한정리: 모집단의 분포와 상관없이 표본크기가 커질수록(30) 표본평균의 분포(통계량)가 정규분포에 가까워짐(데이터 자체 아님!)
- 표준오차: (표본 측정 지표의 변동성을 측정) 여러 표본들로부터 얻은 표본통계량의 변량(표준편차는 개별 데이터 값들의 변량을 의미하여 다름!)
- n제곱근의 법칙: 표준오차 2배 줄이려면 표본 크기 4배 증가
- 카파통계(Kappa): 우연히 정확한 예측을 할 확률
- 상관계수: ex) 상관 관계 많은 정보에 가중치 줄 수 있음
| 피어슨 | 선형적 관계(1이면 직선, 0이면 관계 X, 양수, 음수) , 특이값에 민감(강건X) | ||
| 스피어만 | rank | 로(rho) | (비)선형적 관계, 이산형, 순서형, 순위 계산하고 피어슨 계산(시간+메모리 ↑; 시간은 캐시로 절약) |
| 켄달 | 순서쌍 | 타우(tau) | (x,y)(x,y) xx 커질 때 yy도 커지면 부합, xx 커질때 yy 작아지면 비부합 |
스피어만, 켄들 같은 순위 기초 상관계수는 피어슨보다 더 강건하며 비선형 관계도 다룰 수 있지만, 데이터 크기가 작고, 특별한 가설 검정이 필요할 때 주로 사용됨
- 거리 기반 유사도
| 유사도 | 유클리드(L2) | 맨하탄(L1) | 마할라노비스 | 자카드 | 코사인 |
| 특징 | 정형 아이템 수만큼 다차원 공간 좌표 구성 사용자 간 거리 기반 |
격자 변수간 상관성X |
변수간 공분산 존재> 거리 - 산포(분산)와 양상(공분산) 고려한 상대적 거리 |
집합 데이터 집합 간 교집합 크기 |
벡터(각 차원 상대적 크기 중요) 사용자 간 원점으로부터 사이각 값 |
| 차원 | 小 | 大 | 무관(단, 방향) | ||
| 결과값 | 0~무한대 > 정규화 필요 |
0~1 | |||
| 활용 | 피어슨 계산 안되는 사용자 간 유사도 계산 | 문서간 유사도 클러스터 내부 응집도 |
-
- 집합 기반 유사도: 타니모토( 2 X 교집합 개수 / 합집합 개수 - 1) 노이즈 적을 때
2-2. 데이터의 탐색
- 분포의 이해
- OOD(Out Of Distribution): 분포 외 데이터: 학습 데이터와 다른 분포 갖는 데이터 ↔ ID(in-distribution)
- 검정통계량: 주어진 표본 데이터를 통해 귀무가설을 검정하는데 사용되는 통계적 측도
- 귀무가설이 참일 때 예상되는 분포를 따르게 됨
- 분포: 확률변수가 가질 수 있는 값들과 그 값들이 나타날 확률을 나타내는 함수
- 검정통계량의 분포를 알아야 귀무가설을 검정하는데 사용할 수 있음
- 검정통계량의 값이 해당 분포의 어느 부분에 위치하는지를 통해 귀무가설을 검정할 수 있음

https://sysiphe0.tistory.com/5
선형회귀의 가정 - 정규성, 등분산성, 독립성
정규성(대칭 분포, 평균 = 중앙값) 통계 검정:
- 귀무가설은 "데이터가 정규분포를 따른다"
ㄴ p-value가 유의수준보다 작으면 귀무가설을 기각하며, 데이터가 정규성을 만족하지 않는다는 결론
| 방법 | 설명 | 결과 해석 |
| 샤피로-윌크 (W Shapiro-Wilk) |
작은 샘플 크기에도 강력 | - 검정 통계량(W 값) - 해당 분포에 대한 유의수준(p-value) |
| 콜모고로프-스미르노프 (Kolmogorov-Smirnov) |
큰 샘플 크기에서 효과적 | - 검정 통계량(D 값) - 해당 분포에 대한 유의수준(p-value) |
| 안더슨-달링 (Anderson-Darling) |
- 검정 통계량(AD 값) - 해당 분포에 대한 유의수준(p-value) |
- - 정규성 시각화: Q-Q plot
확률오차의 등분산성 확인 - residual plot(y^ 과 e 잔차 간 패턴 X), Breush-Pagan
독립성 확인
- 예측값과 잔차간의 독립성 : residual plot
- 독립변수와 잔차간의 독립성 : 상관계수, 산점도
- 잔차의 자기상관성 : Durbin watson[0, 4](0에 가까울 수록 양의 상관관계, 2 독립, 4 음의 상관관계)
| 모수적 방법 | 비모수적 방법 |
| - 데이터가 특정 확률 분포(예: 정규 분포, 이항 분포 등)를 따른다고 가정 - 이를 기반으로 모델을 설정하고 추론을 수행 - 해당 분포의 모수(parameter)를 추정하는 방법 - 적은 데이터로도 효과적인 추론이 가능 - 모델의 해석이 상대적으로 용이 |
- 데이터의 분포에 대한 가정을 하지 않고, 추론을 수행 - 데이터에 대한 자유도가 높으며, 분포의 형태나 모수에 대한 가정이 없기 때문에 더 유연한 분석이 가능 - 데이터의 순위 또는 순서에 의존하여 추론을 수행 - 주로 중앙값, 백분위수, 순위 테스트 등의 방법을 사용 |
| t-검정, 선형 회귀 분석, 로지스틱 회귀 | 부트스트랩, 윌콕슨 순위 합계 검정, 커널 밀도 추정 |
| y 변수 형태 | x 변수 형태 | 사용 가능한 모델/통계분석방법 |
| 범주형 | 범주형 | x^2 카이제곱 검정 - 범주형 변수들의 각 카테고리를 독립변수 취급하여 관측 빈도와 기대 빈도 차이 비교(카이제곱 분포는 연속형) <피어슨 잔차들의 제곱합> 카이제곱 통계량: 검정 결과가 독립성에 대한 귀무 기댓값에서 벗어난 정도 측정, 표준화하여 참조 분포와 비교 가능, 적합도검정(관측 데이터가 특정 분포에 적합한 정도) - 낮으면 기대 분포를 거의 따름(높으면 현저하게 다름) |
| 연속형 | t검정, 분산분석 | |
| 연속형 | 명목형 | 분산분석모형(ANOVA: 3개 이상 그룹 간 차이 비교, F-통계량 사용) 로지스틱 회귀분석 |
| 연속형 | 회귀분석, 구조방정식 | |
| 연속형+명목형 | 선형회귀모형 | |
| 범주형 | 연속형+명목형 | 로지스틱회귀, 포아송회귀, SVM |
| 연속형+명목형 | 연속형+명목형 | DT, RF, NN, DL |
※ 범주형 ⊃ 명목형(순서나 계층구조 X) | 순서형
| 확률변수 | 고정 | |||
| 이산 | 베르누이 | 결과 2개, 각 시행은 독립(조건) | ||
| 이항 | 성공실패 횟수 | 확률p | 베르누이 n번 중 k번 성공, n이 크고 p가 0 or 1에 너무 가깝지 않은 경우, 이항분포는 정규분포로 근사 할 수 있음 | |
| 기하 | 성공확률p | 베르누이 첫번째 성공까지 x번 실패(첫 성공 확률 p(x)의 분포) | ||
| 음이항 | 성공확률p (기하 확장) |
베르누이 k번째 성공까지 x번 실패 매개변수: 성공확률 p, 성공하는 횟수 r(목표로 하는 성공 횟수) |
||
| 포아송 | 사건발생 횟수 | 시간과 공간 내에서 발생하는 사건 발생 횟수(시간 주기별 이벤트 모델링) 이항분포 시행횟수 무수히 많아지고, 발생확률은 아주 작은 경우(이항분포 특수한 경우) 단일매개변수: λ = 단위 시간/공간에서 발생하는 사건의 평균 수 평균 = 분산 = λ (λ 커지면 평균 커져 그래프가 우측 이동 + 분산 커져 점점 퍼짐) ㄴ 평균 분산 차이날 때, 회귀계수 추정량의 표준오차가 편향되는 현상 발생 |
||
| 연속 | 정규 | |||
| 지수 | 사건발생 대기시간 |
특정 사건 일어나고 다음에 같은 사건 발생까지 걸리는시간(x≥0) (사건의 발생 횟수가 포아송 분포를 따르면 사건 사이 대기 시간은 지수 분포) α = 1, β = 1/λ 인 감마분포 E(X)=β, Var(X)=β2 |
||
| 감마 | 사건발생 대기시간 (지수확장) |
평균 소요시간이 β인 사건이 α번째 일어날 때 걸리는 시간(x≥0)(지수분포 여러사건으로 확장) 두 매개변수, 양의 실수(복소수), 베이즈 확률론의 사전 확률 분포 정규분포로 해결할 수 없는 부분 보완 |
||
| 베타 | 확률p | 성공 횟수(α-1) 실패 횟수(β-1) |
두 모수, 표본 공간은 0~1사이 실수, 확률(0≤x≤1)에 대한 확률분포 α, β값이 서로 비슷할수록 정규분포에 근사, 분산 커짐 |
|
| t | 집단의 평균이 동일한가(n=30 이상; 표준정규분포) 정규분포와 비슷하지만 꼬리 부분이 약간 더 두껍고 김 |
|||
| x^2 카이제곱 |
집단의 동질성(모집단의 모분산에 대한 가설검정) | |||
| F분포 | 집단의 분산의 동일성 분산의 비율 |
- 사용될 수 있는 ML 모델의 종류 나열
- 시각화 방법 및 그래프 해석
2-3. 데이터 전처리 및 분석마트 구성
- 데이터 전처리
| normalization | [0,1], [-1, 1] 정규화 | 이미지 처리(/255.0) | 이상치 영향 O |
| standardization | 평균=0 / 분산=1 표준 정규 분포 변환 | 가우시안 분포 가정 | 이상치 영향 덜 민감 (왜곡 가능성 존재) |
- 파생변수 생성
- 분석마트 구성
- (불균일) 리샘플링: [성능] undersampling < oversampling(단순 복사, 과적합 가능성, 이상치 교란 위험성), accuracy 高
- SMOTE(과적합 피하기 위한 기술, 소수 클래스 샘플 추출 > 유사 합성 인스턴스 생성, 고차원 효과 X수有)
- 불균일할 경우, Decision Tree, Logistic Regression: 소수 특징 잡은 간주 무시(오분류 가능성)
- 분할: holdout, CV, Bootstrap(63.2%) - 모델 frame 비교 평가 방법, 실제 사용 모델 개발 용도 X
- CV 과정 중 생성된 여러 모형 중 검증결과가 좋은 모형은 모형 성능이 아닌 "데이터 성질"에 의한 결과일 가능성 높음
- 분할 전 정규화를 하면 test 정보가 학습 단계에 유입될 수 있어 분할 > 정규화 순서로 진행
- (불균일) 리샘플링: [성능] undersampling < oversampling(단순 복사, 과적합 가능성, 이상치 교란 위험성), accuracy 高
| 확률적 | 단순임의 | 중복 허락 X |
| 계통추출 | 최초 표본단위 무작위 추출 > 나머지 표본들은 일정한 간격(K) 두고 표본 크기 만큼 | |
| 층화추출 | 상호 이질적인 부 그룹들로 구성, 각 부 그룹에서 독립적으로 임의표본 추출(부 그룹 층화 시 모집단 지식 필요) | |
| 집락표본 | 모집단 여러 군집 > 단순임의> 선정된 군집 전수 조사(과대/과소 위험성) | |
| 비확률적 | 주관, 오차 포함, 오차에 대한 분석 불가능 |
- NLP, NLU
- Text전처리(토큰화, 표제어 등)
서브(-) 샘플링: 자주 등장하는 단어 학습에서 제외하는 기법
워드 임베딩: 단어를 실수 벡터로 표현하는 방법
| TF-IDF | Word2Vec(분류) | FastText | Glove(회귀) | |
| 그룹 | 백오브워즈 | PMI(점별 상호 정보량) | ||
| 특징 | 빈도 | 분포 | 단어 내 서브워드 | 전역통계정보, 출현 빈도 예측 |
| 설명 | 해당 문서에만 나타나는 단어인지 판단 빈도 X log (전체 문서 수/해당단어) |
- 단어 간 의미적 유사성 단어 쌍이 얼마나 자주 같이 등장 CBOW > < Skip-gram 네거티브 학습 서브샘플링 OOV 취약 |
- 단어의 구조적 특성 Word2Vec 유사 n-gram(서브워드) 오타/미등록 단어 강건 softmax(다중클래스분류) |
문맥에서의 빈도/연관성 1) 전체말뭉치 > 동시등장행렬(관계) 2) 임베딩 벡터 학습(손실함수 최소화 - 벡터 간 내적) |
※ PMI: 두 단어가 함께 등장하는 빈도를 활용하여 두 단어 간의 연관성을 측정하는 방법
※ CBOW: 주변 단어로 중간 단어 예측 > < Skip-gram: 중심단어로 주변 단어 예측
문장 임베딩: BERT, GPT
- 문맥 고려 가능
3. 데이터 분석 모델 개발
3-1. 모델의 이론적 이해
- 지도 학습 알고리즘 작동원리
- 분포 기반 통계 언급 후 ML 모델 정의 필요
| 나이브 베이즈 |
- 조건부 확률 계산, 분류 대상별 확률 측정, 큰 쪽으로 분류 - 결과 확률 추정 위해 많은 속성 고려 시 적합 * Gaussian(연속) Multinomial(카운터블) Complement(불균형 강력, 연속, 텍스트) |
* 수치형 속성 범주형으로 이산화 * 절단점 없으면 사분위수 등 사용 |
| Logistic Regression (선형 분류기) |
- 회귀계수 추정 방법: 최대우도추정법(MLE) ※ MLE: 관측된 확률분포와 모델의 확률분포를 비교 가장 일치하는 모수를 찾는 것 1. 각각의 속성에 가중치 곱한 다음 서로 더함 2. 시그모이드 함수에 넣고 0~1 사이 수 구함 3. 0.5 이상이면 1 이하면 0 분류 - 독립변수 선형결합, 사건 발생 가능성 예측하는 통계 기법 - f(x)[-∞,∞] > odds[0< <∞] > Logit[-∞,∞] - log odds와 독립변수 사이의 선형성을 가정함 |
* Odds: 확률 표현법(x/1-x) [0< <∞] = 사건 일어날 가능성 / 일어나지 X 가능성 ㄴ x=0.5 odds=1 ㄴ x < 0.5 완만히 줄어듬 ㄴ x > 0.5 급격히 커짐 * Logit(Log-odds): odds 증가폭 맞추기 위해 ㄴ 입력 [0, 1] 출력 [-∞,∞] p → [logit] → logit → [sigmoid] → p(역함수) |
| Proportional Odds 비례오즈 | - log odds와 독립변수 사이의 선형성을 가정함 가정: 로그 오즈의 비율이 독립 변수들의 값에 관계없이 일정 (모든 설명 변수에 대해 로그 오즈의 비율이 상수로 유지) |
- 종속 변수가 순서형(예: 4점 스케일) - logistic 회귀 모형에 비해 예측에 필요한 회귀계수 숫자가 작음 |
| Decision Tree |
성장 > 가지치기 > 타당성 평가 > 해석 및 예측 - 타당성 평가: 이익도표/위험도표 or 검증 데이터로 평가 |
- 그룹별 종속변수 평균 차이가 커지도록 분리 - 상호 연관성 있는 경우 활용도 大(AND 조건 연결) * (회귀) linear reg 이용 + mean/median/범주형으로 변경 + threshold를 갖는 논리형 변경 |
| Random Forest |
1. bagging으로 bootstrap만듦 2. bootstrap으로 DT 학습 > 예측 3. 1, 2 반복해 예측 모음 4. (회귀) 예측 평균, (분류) 투표 => 앙상블 모델 9. 별도 test data 없어도 모델이 OOB과정에서 제외된 자료로 오류율 계산 |
* Tree = 작은 편향 + 큰 분산 * bootstrap과정은 Tree들의 편향 유지(원본 샘플/특성 유지) + 분산 감소(부분집합 통계치들이 원본 분산 나타내 추정 신뢰성 ↑) * Tree들이 서로 상관화 되어 있지 않으면 노이즈에 강인해짐(비상관화: 다른 데이터로 학습) |
| adaboost | 1. 첫번째 분류기(DT) 훈련 > 예측 2. 잘못 분류된 샘플 가중치 높여 두번째 분류기 훈련 예측 3. 매 스텝 모형 선형결합 > 최종 모형 생성 |
* 유연성: 손실함수 여러개, 기본학습기 제한 없음 * [이진분류] y label = -1/1로 설정 초기가중치 = 1/instance 수(클래수 수 아님) |
| gradient boosting |
- 이전 예측기가 만든 잔여 오차에 새로운 예측기 학습 - 경사하강법으로 가중치 업데이트 |
* 순차 학습 => 속도 느림 |
| xgboost | - GB 기반(속도 느림 보완) - 병렬처리, 결측값 처리 |
* 규제항 추가(과적합 위험 줄임) XGBoost = GBM + Regulation |
| light GBM |
1) 리프 중심 트리 분할 - 각 트리의 리프 노드> 특징들 선택> 분할 2) 히스토그램 기반 학습 - bin 나누고> 누적 히스토그램을 생성 3) 범주형 특징을 자동으로 처리, 결측치 대체 4) 조기 중지: 트리 성장 제한 5-1) 데이터 병렬 처리: 데이터 나누어 스레드/프로세스 병렬 학습 5-2) 트리 병렬 처리: 독립적인 트리들을 병렬로 학습 |
그래디언트 크기가 큰 샘플에 더 집중하여 나무를 성장 |
| SVM | 1) 최적화: 초평면을 찾기 위해 제약 조건이 있는 최적화 문제를 푸는 알고리즘(모델의 가중치와 편향을 조정하는 최적화 과정) 2) 커널 트릭: 데이터 고차원 공간으로 매핑> 선형 분류기로 분류 - 마진, 서포트 벡터(포인트들) - 소프트 마진: 마진 안에도 존재 가능(인스턴스에 패널티 부과) ㄴ 슬랙변수(ξ): 속한 마진 평면에서 떨어진 거리만큼 부여(관측치마다 존재) ㄴ 손실함수: min C * Σξ (C 커지면 ξ 더 많은 벌칙) - Kernel(고차원 특징 공간으로 사상) ㄴ 가우시안 rbf: 성능, gamma(결정경계 곡률, 클수록 모임) |
* 슬랙변수=0 분류 올바른 경우 * 0<슬랙변수<1 분류 위해 마진 허용 * 슬랙변수<1 분류 제대로 안 된 경우 * C 커지면 ξ 더 많은 벌칙 좁은마진경계 * C 작아지면 넘어가는벡터수多(에러 多) |
| K-NN | K: 몇 번째로 가까운 데이터까지 살펴볼 것인가(√데이터개수) - 그룹이 갈리면 다수결 원칙에 따름 - 거리 척도(표준화) |
* larger k: 모든 데이터 다수결 참여(가장 가까운 이웃 X 다수 범주 항상 예측) * smaller k: 노이즈/이상치 영향 |
| reg | 회귀 계수 최적화: 기울기 상승(기울기 방향으로 이동) | 계수 최적화 - 편미분 |
| PCA reg | - 독립 변수만으로 차원 축소한 후 회귀모형 적합 | |
| PLS reg | - 종속변수와의 상관관계 고려하여 차원 축소함 - matrix decomposition 방법, 분할된 projection term들이 서로 공분산 최대화 하도록 분할 결정 |
Partial Least Square |
| 트리 불순도 | 혼잡도 낮도록 선택 | ||
| 이산 | 지니 | 0평등(한가지만) ~ 1불평등(반반) | |
| 엔트로피 | 0평등(한가지만) ~ 1불평등(반반) | 정보이득 = 분할 전 후 엔트로피 차이(gain ratio 사용) | |
| λ^2 p-value | 커지는 방향으로 분할 | 자식 노드간 이질성 큼 | |
| 연속 | F-statistics | ||
| 분산감소량 |
※ 불순도 증가 = 불확실성 증가 = 순도 감소 = 정보 손실 => 분할하지 않는 것이 낮다
※ 선택기준: 1-불순도 = 불순도를 적게하는 방향으로 발전(=집단을 순수하게 만드는 방향으로), np완전문제
| 트리 구성 | ||||
| ML | ID3 | 다중 | 명목형 only, 완벽하게 나눌 수 없는것에 강건X(=오버피팅) | |
| C4.5 C5.0 |
다진 | 엔트로피 | (+) ID3발전, continuous, missing(다른값처리), 완벽하게 나눌 수 없는것에 강건, 가지치기, 중요 속성만 사용 (-) 다수 레벨 속성으로 구분 경향, 과소/과대 적합, 약간 변경 큰 변화 C5.0 - 가지치기 최적화 |
|
| 통계 | CART | 이진 | 범주: 지니 연속: 분산 |
탐욕적 알고리즘, GINI |
| CHAID | 카이제곱 | 입력 반드시 범주형, 가지치지 하지 않고 적당한 크기 성장 중지 |
| 최소제곱법(LS) | 배치경사하강법 | 확률적경사하강법 | 미니배치경사하강법 | |
| 샘플 수 多 | 빠름 | 빠름 | 빠름 | |
| 특성 수 多 | 느림 | 빠름 | 빠름 | 빠름 |
| 외부메모리학습지원 | X | X | O | O |
| 스케일조정필요 | X | O | O | O |
| 하이퍼파라미터수 | 0 | 2 | >=2 | >=2 |
| 모든 데이터셋 매번 그래디언트 계산 | 매 스텝 무작위 1개 샘플 선택 계산 | 작은 샘플 세트 |
※ LS는 행렬기반, 경사하강법은 비용함수 기반; 랜덤 선택하더라도 epoch 만큼 반복해서 데이터 셋 최대한 살핌
- 비지도 학습 알고리즘 작동원리
- 군집분석
| 계층 | 병합 | 계층 순차 군집, 군집 수 정할 필요 X 1. 개별 데이터 단일 클러스터로 지정 2. 각 클러스터 간 유사성 계산 3. 유사성 높은 두 클러스터 합 |
덴드로그램 | |
| 분할 | 중심점 | 군집간 상호 배타적 군집, 군집 수 정해야함 | 중심 기준 분포 | |
| K-means | 1. 그룹 평균에서 각 관측치 거리 산출 2. 거리 가까운 관측치끼리 묶음 |
* 데이터 분할(함수 추정X) * 새로운 데이터 군집 배정 X |
||
| K-Medoids | ||||
| 밀도 | DBSCAN | 밀도 높은 부분 클러스터링 1. 점 p(중심점) epsilon 반경 내 minPts 이상 점 있으면 군집 어디에도 안 속하면 noise point |
서로 근접하게 분포 |
- 차원축소
| PCA | - 정보량 유지하며(분산을 최대한 보존) 컬럼 수 줄여주는 방법, 군집화 활용 가능, 정규화 중요 (+) 축약 후 다중공산성, 자유도 등 문제로 불가능한 회귀분석 시행 할 수 있음 (-) 이상치 심하게 영향 받음, 새로운 축 의미 설명 어려움 |
| MDS | 다차원 스케일링(lsomap, t-sne) |
| ㄴ lsomap | 가장 가까운 이웃과 연결, 지오데식 거리 유지하며 차원 축소 |
| ㄴ t-sne | 비슷한 샘플 가까이, 아니면 멀리, (고차원 공간) 주로 시각화 |
| SOM | 저차원의 격자 형태로 매핑(데이터 간의 관계와 분포를 시각화) |
| AE | 딥러닝 |
-
- 연관분석(Association analysis)
| 지지도 | 신뢰도 | 향상도 |
| P(A∩B) | P(B|A) | P(B|A) / P(B) |
| 특정사건 동시 발생 | A발생 했을 때 B 발생 확률 | 평균 불량 대비 특정 설비에서 불량이 얼마나 더 많이 발생하는가 |
- Loss/Likelihood function 이해
- MLE(Maximum Likelihood Estimation; 최대 우도 추정): 확률 p 추정 방법, 현재 가지고 있는 데이터셋이 나올 확률을 최대화하는 우도(세타)를 구하는 것
- (로그 우도(데이터셋에 대한 로그 확률의 합) 최대화하는 파라미터 값 찾는 방법(파라미터 추정 방법론)
- 최적화 기법: 경사하강법, 뉴턴 랩슨 알고리즘
- MLE 사용: 선형회귀(최소제곱법), 포아송 회귀, 베르누이 분포, 은닉 마르코프 모델(HMMs), 뉴럴 네트워크
- (로그 우도(데이터셋에 대한 로그 확률의 합) 최대화하는 파라미터 값 찾는 방법(파라미터 추정 방법론)
- MLE(Maximum Likelihood Estimation; 최대 우도 추정): 확률 p 추정 방법, 현재 가지고 있는 데이터셋이 나올 확률을 최대화하는 우도(세타)를 구하는 것
| loss function | 하나의 데이터에 대한 실제값(y)과 예측값(y-hat)의 차이 |
| cost function | 전체 데이터의 오차, Loss function의 평균 |
- 모델별 장단점/특징
- ML 모델별 장단점 서술(위치 이동)
- 최종 선택된 모델의 "운영 risk를 정의하고 hedge 방안 서술(위치 이동)
| 모델 | 특징 | 장점 | 단점 | 운영 risk | hedge방안 |
| 선형회귀 | (가정) 1) y, x간 선형성 2) x간 상관관계 없이 독립성 3) 잔차 등분산성 4) 잔차 정규성 *오차: y-모집단회귀식예측값 *잔차: y-표본회귀식예측값 |
교호작용(단일 변수만으로는 알 수 없는 변수들간의 작용) 반영 어려움 | 다중공선성 이상치민감 |
변수 선택/제거, L12 이상치제거 |
|
| 나이브 베이즈 |
- 결함가정에도 불구하고 추측 정확도 민감성에 따라 좋은 성능 - 연속형인 경우 정규분포 가정함 - 스무딩 기법으로 보정 |
- 일부 변수 결측인 경우에도 활용 가능 - 쉽고 빠름 - 변수 서로 독립일 때 성능 좋음(현실 보장 힘든 조건) - 노이즈, 결측 강함 - 적은 학습 데이터로 많은 예측 잘 수행 - 예측에 대한 추정된 확률 얻기 쉬움 |
- (결함 가정 의존) 모든 속성 동등하게 중요 - 수치 속성 많을 땐 이상적X - 추정 확률은 예측 범주보다 덜 신뢰적 - 새로운 데이터 들어오면 조건부 확률 0이라 분류X |
||
| 로지스틱 회귀 |
- 훈련에 대부분 시간, 분류는 빠름 | - 계산비용 적음 - 구현 쉬움 - 결과 해석 위한 지식표현 쉬움 |
- 언더피팅 경향 | 다중공선성 이상치민감 |
변수 선택/제거, L12 클래스 가중치 조정 이상치제거 |
| 트리모델 | - 전처리(스케일링/정규화) 불필요 | - 과적합, 작은 변화 민감 - (회귀) 결정경계 계단식 |
과적합 특정 클래스 편향 |
가지치기 앙상블 |
|
| 트리모델 (회귀) |
분기 기준 SDR(표준 편차 축소) | - 대량 훈련 데이터 필요 - 회귀모델보다 이해 어렵 |
|||
| 결정트리 (DT) |
- 나누어 정복(순환분할(휴리스틱)) - 데이터 추가로 나무 구조 바뀔 수 有 - 하나의 데이터 & 한번의 학습 |
- 플로우 차트(설명력) | - 설명변수(X) 낮은 예측 | ||
| 랜덤포레스트(RF) | - 랜덤 독립변수(표준화X) - 임의 노드 최적화(랜덤 표본) - 병렬 처리 가능 |
- 가장 중요 속성만 선택 - 극단적 큰 속성/예제 데이터 다룰 수 有 - 과적합 少 |
- 임의 데이터 생성으로 처리 데이터 대용량 > 시간 증가 - 해석 어렵(변수중요도는 불순도 감소량) |
||
| adaboost | - 오차 빠르게 적응 - 과적합 영향 덜받음(상대적 늦게) |
- 이상치/노이즈 민감 - 해석 어려움 |
|||
| xgboost | - level-wise(수평으로 키움) ㄴ 균형 만들기 위한 추가연산 > 느림 - 불균형한 데이터에 적합 |
- GB 보다 과적합 강함 - 병렬로 속도 빠름 - 다양한 loss function 사용 - 높은 예측 정확도 - 내부적 교차 검증 가능 - 변수 중요도 시각화 |
- GB 대비 빠르지 다른 알고리즘 대비하면 느림 - 하이퍼파라미터 튜닝 시간 투자 - 해석 어려움 |
커널선택 하이퍼파라미터에 의한 과적합 |
커널선택 파라미터 튜닝 클래스가중치 조정 |
| Light GBM |
- XGBoost 장점 유지시키며 알고리즘 생성 시간 감축(하이퍼파라미터 시간 취약점) - leaf-wise 트리 분할(수직) |
- xgboost 대비 빠름 - 큰 데이터, 적은 메모리 - 카테고리형 피처 자동 변환과 최적 분할 - 고차원/대규모 데이터셋 |
- (데이터 수가 적을 때 10,000) 과적합 - 해석 어려움 |
||
| SVM | - 분류/수치예측 - 스케일링 필요 |
- 과대 적합 경향 적음 - 텍스트 분류 문제 성능 좋음 - 노이즈 강함 |
- 연산 시간 - 해석 어렵(LDA/QDA 대비) |
||
| K-NN (지도) |
- 게으른 학습(인스턴스 기반, 암기) - 비모수 학습 - 샘플수가 많을 때 좋은 분류법(성능비례) |
- 분산에 대한 추정 만들 필요 X(비모수(분포 무관)) - 빠른 훈련, 쉽고 직관적 - x 개수 많아도 가능 |
- 모델 생성 X - 느린 분류, 많은 메모리 - 명목형 속성과 결측 데이터 추가 처리 필요 - 최적 K 선택 어려움 - 훈련데이터 모델 함께 저장 - 해석 어려움 |
||
| K-means (비지도) |
- 군집 개수 알아야 분할(elbow) | - 속도 빠름 | - 무작위 초기화로 최적 군집 못 찾을 수 있음 | ||
| DBSCAN | - 구형 모양 아닌 군집 사용 가능 | - 노이즈 식별 강함 - 군집 수 미리 정할 필요 X |
- 밀도반경과 최소이웃수에 민감 - 클러스터별 밀도 다른 경우 어려움 |
- 모델별 하이퍼파라미터 이해
- 트리모델 과적합 방지 (= underfit - 트리 깊이 얕게 - 학습 속도 빠르게)
- 줄이기: max_depth(깊이 제한), 가지치기(pruning), max_feature(feature 제곱근)
- 높이기: min_samples_split(분할되는데 필요한 샘플 수), min_samples_leaf(말단노드가 되는데 필요한 샘플 수 - 깊이 확장 제한)
- 트리 수 줄이기: num_iter 줄이기, 조기종료
- 하이퍼파라미터 튜닝
- 트리모델 과적합 방지 (= underfit - 트리 깊이 얕게 - 학습 속도 빠르게)
| Grid Search | 모든 경우의 수 |
| Random Search | Grid Search 보다 빠르나 최적해 아닐 수 있음 |
| Bayesian Opt | - Grid/Random Search 서로 종속 X(서로 간 정보 사용 X) - 최적해 보장 X (통계) Aqusition Func 가장 큰 값 나올 확률 높은 지점 - Prior Dist 기반, 하나의 탐색 함수 가정 ㄴ Exploaration(활용): 매번 새로운 샘플로 목적함수 테스트 > 목적함수의 Prior Dist update ㄴ Exploitation(탐색): Posterior Dist 얻은 Global min 가능성 높은 위치에서 알고리즘 테스트 ※ 최적해 가능성 높은 지점에서만 샘플링 할 수 있음(local minima) => Exploaration, Exploitation의 balance point 찾음 |
※ (exploitation)은 주어진 정보를 가지고 최선의 결정을 내리는 것
※ (exploration)은 정보를 더 수집하는 것
| 학습율 | (learning rate) 모델 업데이트 속도 - 크면 손실 함수 줄어들지 않음 - 작으면 학습이 느려짐 - (warmup) 초기 낮은 학습율 사용 > 빠르게 학습률 증가 > 서서히 학습률 감소 방식 |
| 스케쥴러 | 하이퍼파라미터 어떤 식으로 감소/증가 시킬지 결정 - 계단형, 지수형, 코사인형 등 |
| 가중치 감쇠 | (Weight Decay) 모델 파라미터 크기에 제약 , 민감하지 않음, L2 regularization(가중치 제곱을 더해 loss에 추가) - 모델 파라미터 값이 클 경우 모델 사소한 차이에 과하게 반응하며 과적합 가능성 높아짐 |
| 모멘텀 | (momentum) 모델 업데이트를 일정한 방향으로 유지시키는 경향성의 정도 |
-
- (sigmoid/tanh) activation function에서 가중치가 커지면, activation output이 -1 or 1에 수렴하고(값 변화가 적은 지점에 수렴), 따라서 사라지는 경사 문제가 발생할 확률이 높아짐
- 배치 사이즈: 모델 1회 업데이트 하는 과정에서 살펴보는 데이터 수
| 배치사이즈 | 커질 때 | 작아질 때 (오버피팅 ↓) |
| 정밀하게 업데이트 | ||
| GD(기울기 계산 데이터) | 큰 데이터 최적화 | 적은 데이터로 상대적 부정확한 기울기 적은 계산비용 + 여러번 업데이트 |
| 계산 효율 | 높음(100개 한번에) | 낮음(1번씩 100개 |
| 수렴속도 | (한번수행) 빨라짐 파라미터 개선 횟수多 > 시간 ↑ |
|
| 일반화 성능 | 떨어짐(sharp minima에 converge) | |
| 자원(GPU/메모리) | 커질수록 큰 GPU 필요 | 최소 요구 메모리 감소 / 계산비용 ↑ |
| 안정성 | 높음 (강건) | |
| 잡음(noise) | 작아짐 | 커짐 |
| 영향력 | 작아짐 |
- 배치 사이즈가 작아지면 무작위 선택 샘플들이 데이터셋 다양성 잘 반영(더 다양한 패턴 학습 가능)
* 가능하면 전체 데이터로 나눠지도록 하며 아닐 경우 마지막 배치는 버림
- iter(반복): 배치 크기 데이터 한번 살펴보는 것

-
- Bayesian Optimization: 랜덤 서치와 통계적 기법 기반
| HPO | - surrogate model(대리자 모델)을 만들고 대리자를 평가해서 값을 찾음 ㄴ 대리자 모델은 acquisition function(대리자+목적함수+실제데이터기반)이 추천해주는걸로 결정 |
|
| 방법 | Exploitation | 착취: 뒤진데 계속 뒤짐, 현재까지 확보된 경험의 활용 |
| Exploration | 탐험: 안 뒤진 불확실성 높은곳 뒤짐, 손해를 감수하고 탐색을 통한 경험 축적 | |
| EI | Expected Improvement | 착취 탐험 일정 수준 포함하게 설계한 Acquisition 함수(대리자 모델이 목적함수 대해 실제 데이터 기반 다음번 조사 X값을 확률적으로 추천해주는 함수) - Exploitation와 Exploration 일정 수준 포함 설계 |
| Entropy search | 엔트로피가 낮은 구간(제일 모르는 구간 찾는 것) > 편차 높은 x return | |
| Upper confidence bound | x 지점에 대한 가우시안 분포가 제일 최고 지점인 부분 return | |
- Explainable AI 알고리즘
- SHAP: 단순화 된 input을 넣어 대리 모델 찾는 것(Local 설명 기반으로 전체(f: black box 모델) 해석)
- 개별 row 마다 종속변수에 대한 기여도 산출
- (+) 개별 관측치에 대한 X인자가 Y값을 도출하는데 기여한 기여도를 산출하여 다양한 차원 해석 가능
- (-) 연산 속도 많이 느림(학습보다 느린 경우 많음)
- 단순화 된 input을 정의하기 위해 f의 값이 아닌 f의 조건부 평균 계산
- SHAP value: 어떤 특성의 조건부 조건에서 해당 특성이 모델 예측치의 변화를 가져오는 정도
- Base value: 아무 특성 모를 때 예측된 것; background dataset 예측값 평균, 조정해서 local 특성 파악
- 모델 예측값: SHAP value + base value
- 변수 중요도: E(|SHAP Value|)
- Kernal(Linear LIME + Shaply value), Tree, Deep
- Feature Importance 한계(Model-specific)
- 랜덤포레스트 Feature Importance - 다소 biased
- high cardinality(연속형 or 카테고리 개수가 많은 변수) 변수 중요도 부풀릴 가능성 높음
- 지니 불순도 기반 트리 모델 변수 중요도: 연속형 변수 우대 평가
- 부모 노드 가중치 불순도에서 자식노드들의 가중치 불순도 합 제거한 값
- train 데이터 학습 과정에서 얻어진 결과로 test 데이터 안 중요 데이터가 중요하게 계산될 수 있음
- 랜덤포레스트 Feature Importance - 다소 biased
- Permutation Feature Importance(Model-agnostic)
- 학습시킨 후 적용(Post-hoc)
- 특정 피처 안 썼을 때, 성능 손실에 얼마나 영향주는지
- 피처를 무작위 (분포)로 섞어서(permutation) 그 피처를 노이즈로 만드는 것
- 피쳐들 간의 교호작용(의존관계)을 끊음
- (+) 재학습 필요 없음
- Drop Column Importance
- 모든 변수 사용했을 때 - 특정 변수 빼고 재학습 차이
- (+) 직관적 (-) 변수 개수만큼 재학습 필요, Computation 관점으로 비효율적
- 모든 변수 사용했을 때 - 특정 변수 빼고 재학습 차이
- MDI(Mean Decrease in Impurity) Importance
- 각 변수 split 될 때 impurity 감소분의 평균
- PCA
- SHAP: 단순화 된 input을 넣어 대리 모델 찾는 것(Local 설명 기반으로 전체(f: black box 모델) 해석)
- 텍스트 분석(문서분류)
- 텍스트 분석(감성분석)
- 텍스트 분석(토픽모델링)
3-2. 모델의 평가 및 활용
- 모델의 진단
- over/underfitting & Bias/Var
| bias | 모델의 예측값과 실제 정답의 차이의 평균 |
| variance | 입력 데이터에 대해 예측값이 얼마만큼 변화할 수 있는지에 대한 양(amount)의 개념 |
| overfit | high variance | 모델 복잡 | 트리 깊이(불순도) | SVM C bagging |
노이즈까지 학습 |
| underfit | high bias | 모델 단순 | K-means K | boosting |
[overfit] > 데이터 증강|차원축소|규제 > [underfit]
■ underfitting: 충분히 낮은 training error에 도달하지 못한 경우
■ overfitting: 태스크를 일반화하지 못하고 알려 준 데이터와 정답을 그냥 외웠을 뿐
[good fit] = low bias + low variance
※ 분산 편향 - trade off 관계 (전체 에러 = 절대 줄일 수 없는 오차 + 분산 + 편향)
※ 편향 큰 모델(선택) > 분산 큰 모델 - 오컴의 면도날(간단한 것 선택)
※ 학습 데이터 증가: bias 변화없음, variance 감소함
| random error | 측정 시 발생하는 불확실성으로 인해 발생 > 측정값이 무작위로 변하는 오차 |
| systematic error | 측정 시 발생하는 시스템적인 문제로 인해 발생 > 측정값이 일정한 방향으로 편향되는 오차 |
※ 딥러닝은 training set이 random error에 대해 견고, systematic error에는 민감
- 모델의 평가
- Precision/Recall
| 예측값 Prediction |
||||
| 예측값 | Positive | Negative | ||
| 실제값 Real |
Positive | TP | FN (type 2 error) | Recall 재현률 |
| Negative | FP (type 1 error) | TN | ||
| Precision 정밀도 | ||||
■ Recall(검출율): 불량 판매 시 타격 큼. 사람이 재검수해도 되니 낌새만 있으면 다 탐지
■ Precision(정밀도): 불량 예측 많다고 다 못봄. 아무거나 불량이라고 하면 곤란
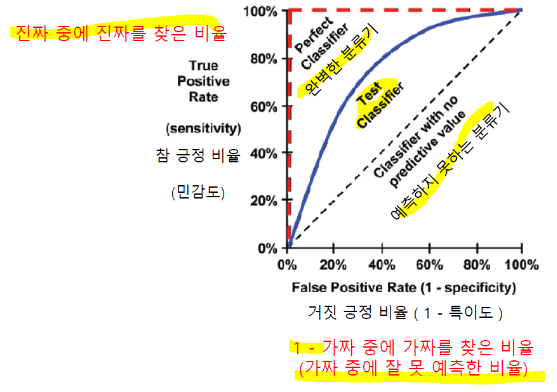
■ ROC

| Macro | Micro |
| 클래스별 성능을 독립적으로 계산하고 평균 - 각 클래스의 성능을 동등하게 중요 |
클래스별 성능을 모두 더해서 전체적인 성능 - 클래스별 샘플의 개수가 다르더라도 전체적인 성능을 고려 |
| activation | loss | ||
| Sigmoid | MSE | binary, regression | 0~1 범위, sigmoid -2~2 이외 미분값 거의 0 => 학습속도 저하 |
| Sigmoid | Cross Entropy | binary | 0~1 범위, convex |
| Softmax | Categorical Cross Entropy | multi class | 오차 크면 더 많이/적으면 더 적게 업데이트 => 모델 수렴 빠름 |
| binary cross entropy | multi label |
※ CE(binary classfication) CCE(multi class classfication)
| 도함수 y | ||
| Sigmoid | (문제) 몹시 크거나 작은 값을 입력으로 받는 경우, gradient가 거의 0에 가까워짐(기울기소실), 계산 다소 복잡 | 0~(약)0.3 |
| tanh | -1~1 (문제) sigmoid 동일(기울기 1 이하) | 0~1 |
| ReLU | gradient가 0이 되는 경우 X, 계산 간단, sigmoid, tanh 대비 6배 빠르게 수렴 | x > 0, 1 |
s-curve fitting
- 시간이 지남에 따라 진행 모델링(예: 프로젝트 완료, 인구 증가, 전염병 확산 등)
loss 함수: 원하는 값이면 작아야하고, 원하지 않는 값이면 커야함
| Quadratic | 정답 실수형인 경우에도 가능 | sigmoid와 같이 사용 시 수렴 더디게 함 |
| CE [이진] | Quadratic 대비 수렴 빠름(-log함수) | 최근 DL에서 Multiclass NLL loss와 거의 동일 사용 |
| NLL [Multi-class] |
[Negative Log Likelihood] Softmax 함수와 결합 사용 시 모델 수렴을 빠르게 함 |
정답에 해당하는 클래스만 고려 이진분류의 경우 CE와 동일 |
-
- 회귀 평가
- MAPE(%): [0, 100] = 1/n Σ |y^-y / y|
- 군집 평가
- SSE(작을수록): 중심 가깝, 군집 수 늘이면 줄지만 개수 유지하며 질 향상
- elbow: 클러스터 내 오차제곱합 최소
- 회귀 평가
- 모델의 결과해석
- OLS Regression 최소자승법(OLS: Ordinary Least Squares)
| DF Residuals | 잔차 자유도 | 표본 수 - 종속변수 개수 - 독립변수 개수 (변화할 수 있는 총 원소 개수 - 제약식의 개수) |
| DF Model | 독립변수 개수 | |
| R^2 | 설명력 | 전체 데이터 중 모델이 설명할 수 있는 데이터 비율 R^2 = SSR(예측-평균) / SST(실제-평균) = 1-SSE(오차) / SST = (y 변동량 대비) 회귀선에 의해 설명되는 변동 / 전체 변동 (음수) 평균보다 모델 성능 떨어짐 * 상관관계 높을수록 1에 가까움 [0, 1] * √R^2 = 두 변수 상관계수 |
| Adj R^2 | 설명력 | R^2 설명변수 늘어나면 (무조건) 값 커져, 자유도로 나눈 Adj R^2 많이 사용 ㄴ 독립변수 2개 이상 |
| F-통계량: | 회귀식 적절성 | 회귀식으로 설명 가능한 데이터와 그렇지 않은 데이터 분산 비교, 0일수록 적절 |
| Prob(F-통계량) | 회귀식 유의미성 | 0.05 이하면 변수까리 매우 관련 있다고 판단 |
| AIC | 모델 평가 | Akaike Information Criterion = 2(모델파라이터#) - 2ln(모델최대우도) 표본 개수와 모델 복잡성 기반 모델 평가, 낮을수록 좋음 종속변수의 실제 분포와 모델의 결과와의 불일치에 기반 하나의 데이터 셋, 다른 설명변수, 동일 모형(서로 다른 모형 비교 X) |
| BIC | 패널티 | Bayesian Information Criterion = (모델파라이터#)ln(샘플수) - 2ln(모델최대우도) AIC+패널티, AIC보다 평가 성능 좋음, 낮을수록 좋음 |
- 변수선택(Feature Selection): 작을 수록 적절한 설명력(가능도=우도) + 적절한 복잡도(변수 개수), Stepwise
| coef(coef) | 회귀 계수 | |
| std err | 표준 오차 | 계수 추정치의 표준오차, 값이 작을 수록 좋음 |
| t | 상관관계 | t-test, 독립변수와 종속변수 사이 상관관계, 값 클수록 상관관계 큼 |
| p-value(P>|t|) | 유의확률 | 독립변수들의 유의 확률, 0.05보다 작아야 유의미함 |
| [0.025 0.975] | 신뢰구간 | 회귀 계수의 신뢰구간 |
| Omnibus | 정규성 | 디아고스티노 검정(D'Angostino's Test), 비대칭도와 첨도를 결함한 정규성 테스트, 클수록 정규분포 |
| Prob(Omnibus) | 디아고스티노 검정이 유의미한지 판단(0.05 이하면 유의미 판단) | |
| skew | 왜도 | 평균 주위의 잔차들이 대칭하는지, 0에 가까울수록 대칭 ㄴ > 0 positive(오) 오른쪽 긴 꼬리 - 로그/루트/역수 ㄴ < 0 negative(왼) 왼쪽 긴 꼬리 - 제곱/지수 |
| kurtosis | 첨도 | 잔차들의 분포 모양, 3에 가까울수록 정규분포(음수-평평, 양수-뾰족) |
| Durbin-Waston | 잔차 독립성 | 더빈왓슨 정규성 검정, 잔차의 독립성 여부 판단 1.5~2.5 잔차 독립적, 0 or 4 가까우면 잔차들이 자기상관 가지고 있다고 판단 |
| Jarque-Bera | 정규성 | 자크베라 정규성 검정, 값이 클 수록 정규분포 데이터 사용 |
| Cond. No | 다중공선성 검정 | 독립변수간 상관관계 있는지, 10 이상이면 다중공선성 있다고 판단 |
- 선형회귀모형(Y= α + βX + ε) β=0에 대한 통계적 유의성 검정 실시, X가 Y에 유의미한 영향 미치는지 판단
- Q. 모델이 오차를 얼마나 해결?
- 검정통계량: 모델이 설명하는 변동 / 설명하지 못하는 변동 = 효과(신호) / 오차

SST SSR SSE
* SST: 종속변수의 분산 = 평균과의 차이를 제곱한 것의 합 으로 추정
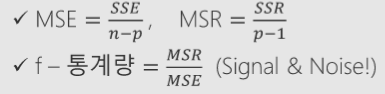
MSE MSR MSE F통계량
SST SSR SSE
- 모델별 보정 및 재학습 방안
| 앙상블 | bagging | boosting |
| 특징 | 병렬 앙상블(각 모델 서로 독립) categorical - voting | continuous - mean |
연속sequential 앙상블(이전 모델 오류 반영) 단계별 classifier 합쳐 최종 classifier 구함 |
| 목적 | variance 감소 | bias 감소 |
| 적합한 상황 | low bias + high variance - 오버피팅이 문제 |
high bias + low variance - 개별 결정 트리 낮은 성능이 문제(weak learner) |
| sampling | random sampling | adaboost, gradient boosting |
| 장점 | 성능 좋음 | |
| 단점 | 속도 느리고 오버피팅 가능성 |
※ weak learner: 데이터 작은 변화가 분류 모델 큰 차이 야기하는 분류 알고리즘
| adaboost | gradient boosting | |
| weak learner | stump: 한개 노드 2개 가지 갖는 매우 작은 DT | restricted tree: max num of leaves로 성장 제한 둔 DT |
| leaf* + restricted tree (with 동일 lr) * leaf: 첫번째 week learner는 모든 샘플의 output 평균을 값으로 갖는 하나의 leaf |
||
| Predicted value | output 각자 실제 output 예측 => 가중평균 |
Pseudo-residual 각 restricted tree 예측값은 실제 output 과 이전 모델 예측치 사이 오차 > scaling > sum |
| Model weight | 다른 양을 가지는 stump가 모델별 다른 weights | 동일 모델 weight(learning rate) |
| optimizer | |||
| momentum | 관성 > 방향 | 과거 파라미터 업데이트 누적 + 방향성 반영 | * SGD |
| adaptive | 크기/사이즈 | 파라미터 업데이터 > learning rate 줄어들며 미세 조정 | * AdaGrad * RMSprop: 지수이동평균 |
| momentum + adaptive | * Adam |
- 선형회귀 규제
| l1 라쏘 Lasso | l2 릿지 Ridge (Weight decay*) | 엘레스틱넷 |
| 절대값 | 제곱 | r: 혼합비율 |
| - 가중치를 0으로 푸시하여 희소 모델 유도 - 릿지보다 최소값 근처 기울기 큼(급속히 w=0) - α 클수록 w=0으로 향하는 정도/속도 커짐 - 중요도 낮으면 0으로 축소 - l2 보다 이상치 robust - 희소성(0이 되는 weight 많음 - 제거가능) => weight 0 제거로 오버피팅 방지 기능 |
- 가중치 매개변수를 희소하게 만들지 않고, 패널티 부여(작은 가중치에 대해서는 패널티 0) α=0 선형회귀 α=1 학습 파라미터 증가폭 커져 그래프 모양 단순해짐 WD*: 불필요한 weight 0근처로 유도, capacity 줄이는것과 유사 효과 - 이상치 영향 많이 받음 |
r=0 릿지 r=1 라쏘 |
※ 가중치 감쇠: 이상치 적당히 무시: l1, 이상치 신경써야하면 l2
ㄴ예시) l2(0.001): 네트워크의 전체 손실에 층에 있는 가중치 행렬의 모든 값이 0.001 * weight_coefficient_value**2만큼 더해짐; 훈련할 때만 추가 > 테스트 단계보다 훈련 단계에서 네트워크 손실이 훨씬 더 큼
- 나이브 베이즈 스무딩: 데이터 빈도 보정
| 라플라스 | 출현빈도 + 일정값(출현하지 않아도 확률 0 되는것 방지 -> 일반화 특성 학습 가능=오버피팅 방지) |
| Lidstone | 단어마다 서로 다른 보정값(라플라스보다 유연) |
| Add-k | + 0보다 큰 임의의 k (k값 크게 설정 -> 데이터셋 작은 경우에도 일정 확률값 보장) |
| Good-turing | 기존 출현하지 X > 새로운 빈도수로 추정(데이터셋 나타난 빈도수 바탕) |
- 규제(정규화)
1) 모델에 범위 제한 constraints 부여
2) 목적함수에 파라미터 범위 제한하도록 동작하는 term 추가
3) 학습데이터 설명할 수 있는 여러가정 조합
4) 학습데이터 분포에 대한 사전지식을 활용해 추가 학습 데이터 생성
5) noise로 정규화 효과
- 모델별 활용 방법
- 나이브베이즈: 실시간 분류, 텍스트 분류(스팸필터링, 감성분석), 추천 시스템
4. 신기술
4-1. 데이터 분석 관련 신기술
- AutoEncoder 기본개념 및 활용방안
- 기존 PCA(선대, 최적화 등 이론 관련됨)과는 다르게 데이터로만 직관적 이해 가능
- latent representation coding / reconstruction error
- 기존 PCA(선대, 최적화 등 이론 관련됨)과는 다르게 데이터로만 직관적 이해 가능
- 전이학습 기본개념
- Finetuning 기본개념
- lr 크면, pretrain이 새로운 데이터셋에 맞게 업데이트 됨. ↓
- 언어모델 사용방법
- Data Drift 기본개념의 이해
- Model Drift: 입력 데이터 변화 or 입출력 관계 변화로 인한 모델 성능 저하 가능성 판단
- Data Drift(feature drift/covariate shift), Concept Drift, Label(Target) Drift, Prediction Drift(Concept drift의 시그널 가능성 존재)
- Model Drift: 입력 데이터 변화 or 입출력 관계 변화로 인한 모델 성능 저하 가능성 판단
| Data | - 입력 데이터 통계적 분포 변화 ㄴ Periodic(계절 같은 시간 변화) / Instantaneous(코로나 같은 새로운 도메인) / Temporary(시간/공간 변화 X 기분 같은 임시) / Gradual(시간이 지남에 따른 사용자 선호도 변화) |
|
| Concept | - 입력 데이터의 통계적 분포와 예측하려는 정답 라벨의 의미/개념/통계적 특성(관계성/해석방법)의 변화 - 시간이 지남에 따라 모델이 예측할 대상 변수의 통계적 특성이 변화 |
|
| Domain | - 학습데이터 분포와 테스트 데이터 분포 차이 |
- MLOps 기본개념
- 머신러닝을 위한 데이터 수집, 분석, model training, 평가 검증, 배포 등의 프로세스를 자동화하고,
- 이를 유지관리하고 모니터링하는 머신 러닝 엔지니어링 협업 기능
- MLOps 구성요소 이해
- 구성원: 데싸, DevOps 엔지니어, IT
- ML Pipeline: CI + CD + CT(Continuous Training)
- CT: 모델이 Production 단계에서 새로운 데이터로 학습하여 만들어낸 새로운 모델을 배포하는 과정 반복
- Cycle: EDA > Data Prep > 모델 훈련 및 튜닝 > 모델 검토 > 추론 > 서빙 > 배포 / 모니터링 > 자동 재훈련
- 강화학습 기본개념의 이해
- 환경(물리법칙/사회규칙)안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동등 중 보상을 최대화 하는 행동 혹은 행동 순서를 스스로 선택하도록 학습시키는 방법
- 학습 초반에는 Explore, 학습 진행 될 수록 Exploit에 가깝게 설정
- 복잡한 상황) 현재 선택 행동이 미래 순차적 보상 영향 > agent는 당장의 보상 아닌 최종 미래 보상 극대화 전략
- 희소 보상 문제: 중간 보상, 모사 학습(사람이 조정한걸 메모리 저장 학습 활용), 탐색 범위 넓히기(학습 초기 랜덤 행동 비율 늘이기)
- 환경(물리법칙/사회규칙)안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동등 중 보상을 최대화 하는 행동 혹은 행동 순서를 스스로 선택하도록 학습시키는 방법
통계
시계열
패턴(3): 추세, 계절성, 주기성
분해: 패턴(3)을 분리하고 독립적으로 분석하기 위한 기법, 분리 후 잔차를 계산하여 불규칙한 패턴 분석
자기상관계수: 시간 간격 일정 두개의 관측치가 서로 상관 관계가지는 정도(일주일 간격 수집된 데이터 관계)
상호상관(비교상관, 교차상관)계수: 시간 간격이 일정하지 않은 경우
정상성: 시간이 흘러도 통계적 특성 변하지 않는 성질(평균 분산 일정, 자기상관계수 일정 - 과거 미래 상관 X, 시간 따른 분산 일정)
비정상성: 시간에 따라 통계량 계속 변해 예측 어려움. 시계열 데이터 분석 위해 정상성 검정 선행
ex) 연간 매출액 - 월간 매출액 공분산 다를 수 있음. 2021/01 매출액과 2021/02 매출액간 공분산은 달라지지 않음, 그래서 공분산 대신 자기상관계수 사용하여 시계열 상관관계 분석함
ㄴ 공분산: 두 변수 분포 함께 변화하는 경향 | 자기상관계수: 시점 간 관계
지수 평활법: 과거 데이터에 대한 가중치를 지수적으로 감소시키며 평균을 계산하는 방법
ㄴ Holt-Winters: 예측식 + 평활식(수준, 추세, 계절 성분)
AARIMA: ARIMA + exogenous변수(시계열 데이터에 종속적이지 않은 외부 변수)
ARIMAX = AR + MA + 설명변수 > 다변량(독립변수가 종속변수 영향-인과관계)
VAR(Vector Auto Regression) > 다변량(상호작용/동적관계)